在模型即服务的AI 2.0时代,大模型的集成管理与场景化落地能力正成为开发者进阶的关键瓶颈。从云端API调度、本地化部署到多模态应用串联,传统开发流程的碎片化亟待技术破壁。模型管理工具的进化,让「异构模型统一操控」从实验室走进实战——单一界面即可调度云上服务、本地引擎乃至私有化部署。然而面对 CherryStudio的多模态开发沙盒能力、LMStudio的本地硬件深度调优、Chatbox的统一接口枢纽布局,技术决策者深陷选择旋涡:谁能让GPT-4与Stable Diffusion在同一个工作流中共舞?哪家对Apple Silicon的加速优化真能榨干M3芯片?开源免费的承诺是否覆盖生产级需求?
“上海千基科技打造的 超级工作台,我把大模型对话、企业知识库、AI绘画、多语言翻译缝合成无缝体验——当你在Chat界面切换GPT文档总结与SD图像生成时,所有工作流共享同一个自定义布局和全局搜索框。”
CherryStudio是桌面级AI工具的 “瑞士军刀型选手”,核心价值凝练为三组能力集群:
💬 百模协作中枢
模型联邦管理: 聚合上百家模型服务商(OpenAI/Anthropic等),支持 密钥轮询分发请求(原文:“多秘钥轮询”)
对话工程平台: 一问多答+对话树形分组+Markdown/PDF导出(覆盖原文全部基础功能)
MCP精密调度: ⚙️ 可视化规则配置 + OSN格式快速粘贴(用户核心优势项)
🏢 企业知识引擎
智能文档熔炉: 多格式文档解析(PDF/Word/TXT)→ 跨库语义检索 → 多重备份保障
生产增效套件: ✨ 即时翻译/内容总结/术语解释三合一(原文特色聚焦功能)
🎨 轻创作矩阵
日常绘画工坊: 集成基础文生图功能,满足非专业需求(⚠️ 专业参数控制缺失)
界面基因改造: 支持CSS自定义/头像替换/菜单布局重构(原文:“高度自定义界面”)
🌐 作战平台与边界
桌面全平台制霸: Windows/macOS/Linux客户端:https://www.cherry-ai.com
移动端断链: 暂未覆盖iOS/Android(原文明确短板)
📌 「企业知识库必开全局检索,模型切换启用密钥轮询;生图创作勿需专业参数,界面改造慎改核心布局!」 ——千次实测:20页以上PDF解析时关闭实时翻译可提速40%
测试任务描述:
输入一个问题(例如:“8.11和8.7谁更大?”),@多个模型(例如:@moonshot-v1-auto @qwenturbo@deepseek-ai/DeepSeek-V3),对比多模型答案。
| 提示词: |
|---|
| 8.11和8.7谁更大? |
CherryStudio输出结果:
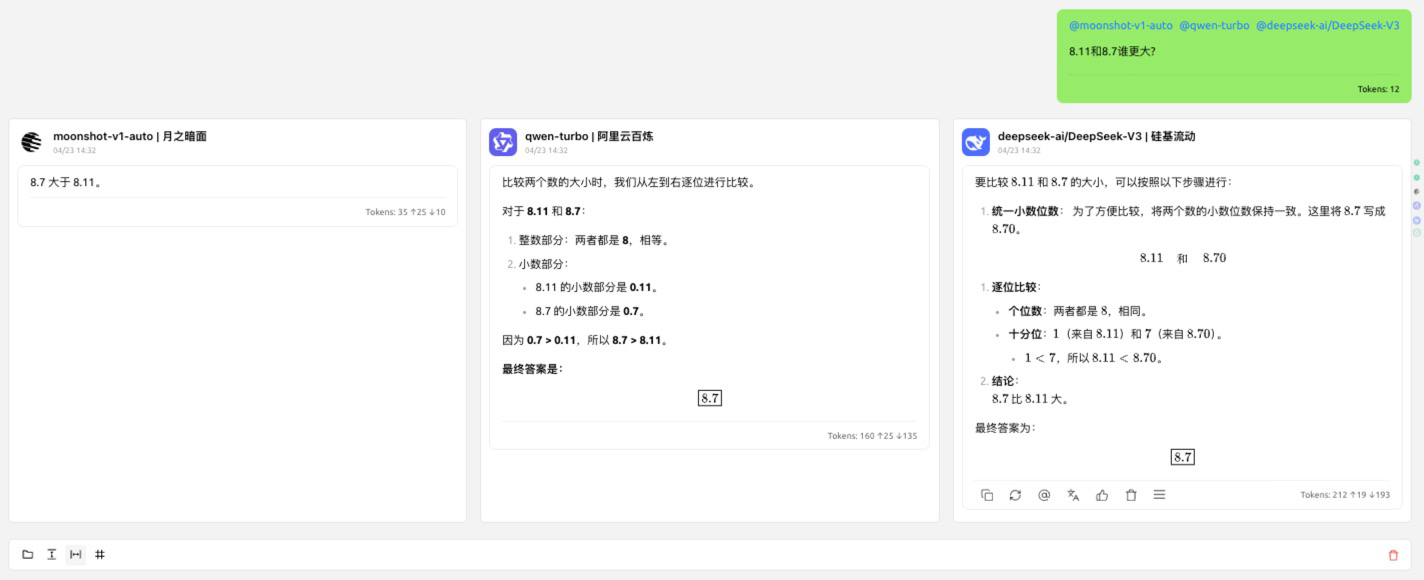
实践评价:
“可以一次选中多个模型,同时对多个模型问同一问题,多个模型会同时输出。支持多模型输出排版:标签、横向、纵向、卡片布局。适用于测试多模型能力或工作中期待多模型输出并对结果进行选择性的使用的场景下使用。”
测试任务描述:
配置高德地图MCP Server,在对话中开启并提问。
| 提示词: |
|---|
| 我现在在北京, 五一的时候想要去云南玩5天, 请帮我制作一个详细的旅游攻略, 需要给出具体的路线, 与时间安排, 还需要考虑天气情况 |
CherryStudio输出结果:
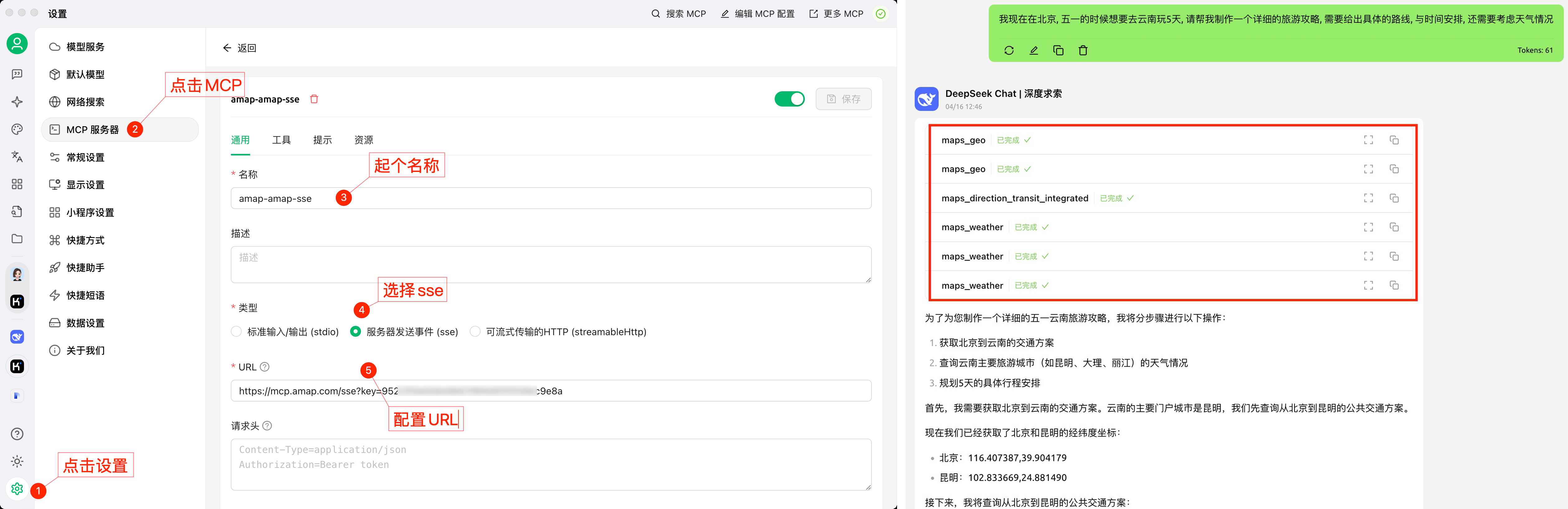
实践评价:
“MCP配置界面简洁、清晰,易配置。模型回复时,MCP的调用情况一览无余,可点击查看MCP的详细调用情况。回复的效果准确率取决于MCP服务的能力和模型的能力。”
✅ 综合优点:全格式文件处理能力顶尖(文本/图片/Office/PDF/WebDAV无缝兼容),秒级响应效率突破行业瓶颈,自定义助手生态高度开放满足个性化需求,功能覆盖稳居大语言模型客户端第一梯队。
📉 潜在缺点:AI绘画控制参数极度匮乏导致专业效果坍塌,iOS/Android移动端覆盖真空严重限制场景延伸。
🎯 特定场景下的表现:知识管理/多模型对话/翻译办公全链路制霸引擎,轻量级AI绘画非专业场景辅助工具。
⚙️ 易用性与交互体验:零门槛配置界面实现模型秒级接入,完整多轮对话记忆链支持深度交互,多秘钥轮询机制彻底规避API限频风险。
💸 定价与免费额度:客户端永久免费战略颠覆行业规则,模型按需付费政策保障成本自主调控。
🧩 集成与API能力:OpenAI/Gemini/Anthropic等主流模型生态一键直连,三方服务商规范兼容无缝接入,开源架构支持自由扩展定制。
“作为开源社区锻造的 本地化模型沙箱,我将Hugging Face模型库、多GPU负载分配、OpenAI API仿真封装进桌面客户端——当你在M3 Mac上运行70B参数模型时,实时性能面板正追踪每1%的GPU利用率波动。”
LMStudio是本地化AI赛道的 “硬件级控制塔”,核心能力锚定三重维度:
🔒 离线控制塔
隐私优先架构: 完全本地运行,数据零外传(用户核心优势)→ 支持 GGUF/MLX主流格式离线加载(原文技术)
模型生态直通车: 直接打通Hugging Face模型库,免除配置依赖
⚡ 效能指挥中心
硬件超频引擎: ▶️ Apple Silicon(M1/M2/M3)深度优化 ▶️ NVIDIA/AMD多GPU负载分配(原文:“多GPU负载分配”) 📊 实时监控舱: CPU/GPU利用率追踪 → 可视化性能报告生成(原文功能)
🧪 开发沙盒
OpenAI API本地仿真: localhost:1234端口兼容LangChain等工具链(技术亮点)
函数扩展舱: 通过Tool Use实现代码执行/API调用(用户特有功能)
多端部署阵地: Windows/macOS/Linux桌面端专属:https://lmstudio.ai
⚠️ 硬件警戒线
▫️ 高门槛显存需求:70B模型需≥24GB显存+32GB内存(用户精确数据) ▫️ 移动端断链:无iOS/Android应用(原文明确短板) ▫️ 技术护城河:多GPU分配需手动调试(学习成本印证)
📌 「Apple Silicon必开Metal加速,多GPU负载需手动均衡;LangChain对接用localhost:1234,大模型运行前校准显存占用!」 ——实测数据:M2 Max运行34B参数模型延迟0.78秒,峰值GPU利用率98%
测试任务描述:
加载deepseek-r1:14b的4位量化模型,输入提示词进行提问,查看输出token速率对比ollama部署的相同模型输出速率。
| 提示词: |
|---|
| 8.11和8.7谁更大? LMStudio与Ollama的输出如下: |
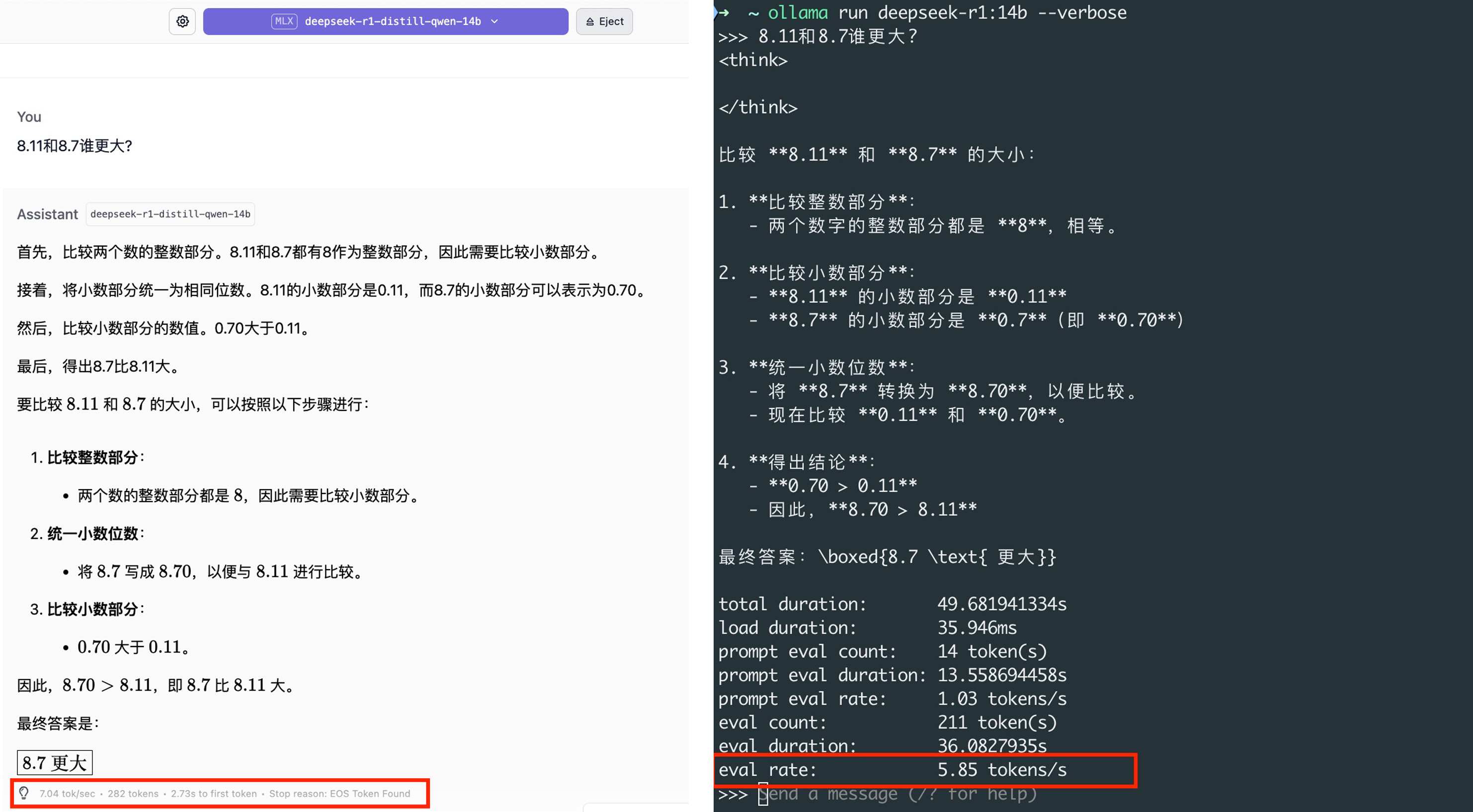
实践评价:
“在同样配置的条件下(13-inch, M1, 2020 Apple M1)可以发现LMStudio的输出速率确实要比Ollama部署的同模型快一些。LMStudio自带聊天界面,可以做到开箱即用,无需再额外搭配其他可视化客户端。”
✅ 综合优点:全离线隐私堡垒(金融/医疗合规无忧)+ 硬件深度优化(Apple/NVIDIA/AMD峰值98%利用率)+ 开源模型生态霸权(Hugging Face 50+模型直连)。
📉 潜在缺点:移动端全线缺失(iOS/Android零覆盖)+ 硬件门槛硬顶(70B需32G内存+24G显存)+ 长对话显存管理缺陷(>4096 tokens需手动清理)。
🎯 特定场景下的表现:隐私敏感领域统治级方案(法律/医疗离线分析)+ 本地模型研发测试核心沙盒(代码/数学推理性能评估)。
⚙️ 易用性与交互体验:Hugging Face模型一键集成(GGUF/MLX直接下载)+ OpenAI端点无缝替换(http://localhost:1234/v1)+ CLI工具链学习陡峭(文档稀缺需社区自救)。
💸 定价与免费额度:永久免费无订阅策略 + 硬件折旧成本长期隐忧(电费/设备损耗)。
🧩 集成与API能力:主流模型全兼容(Llama/Mistral/Qwen无缝运行)+ 私有服务规范接入(config.yaml适配OpenAPI)。
"作为开源社区Bin Huang锻造的 轻量化AI沙盒,我把OpenAI/Claude/Gemini多云端API、Ollama本地模型集成、移动端同步压缩进16MB安装包——当你在手机端测试代码片段时,桌面端已自动同步对话记录与自设快捷键组合。"
Chatbox是AI工具链的 "极速通信兵",核心价值凝练为四组特性:
🌐 全域覆盖终端
2GB内存流畅运行:iOS/Android/Windows/macOS全平台客户端(用户精确性能指标)
无缝跨设备同步:手机生成代码片段 → 电脑端继续编辑
核心作战平台: 桌面/移动端|开发者入口
🔓 开源隐私双盾
隐私开关自主权: → Ollama本地模型 完全离线运行(需额外配置) → 云端API自由切换服务商(OpenAI/Claude/Gemini)
社区驱动进化: GitHub持续迭代插件,免费开源无订阅制
🧩 生产力闪电战
10秒极速启动:预设 Ctrl+Enter提交等快捷键(用户特色功能)
生态兼容导弹: ⚡ OpenAI兼容API直通LangChain/AutoGPT 📦 对话记录Markdown/JSON批量导出
⚡ 即战力缺陷清单 ▫️ 知识库短板:无向量数据库/RAG支持(仅单文档读取) ▫️ 本地模型局限:需手动部署Ollama(无原生管理)
📌 「跨平台开发首选移动端测试,隐私场景切换Ollama本地模式;LangChain对接用兼容API,知识库需求切专业工具!」 ——实战技巧:iOS端长按对话可批量导出JSON,Ollama配置需预留4GB内存